🧮 Machine Learning & Big Data
Reinforcement Learning, Transfer Learning, Fine-Tuning, LSTM, Hadoop, MapReduce, NameNode, data analytics for UPSSSC AGTA.
What is Machine Learning?
Machine Learning (ML) is a branch of Artificial Intelligence where computers learn from data and improve their performance without being explicitly programmed. Instead of writing rules manually, we feed data to an algorithm and it discovers patterns on its own.
Example: A spam filter learns from thousands of emails which ones are spam and which are not — it gets better over time as it sees more data.
Types of Machine Learning
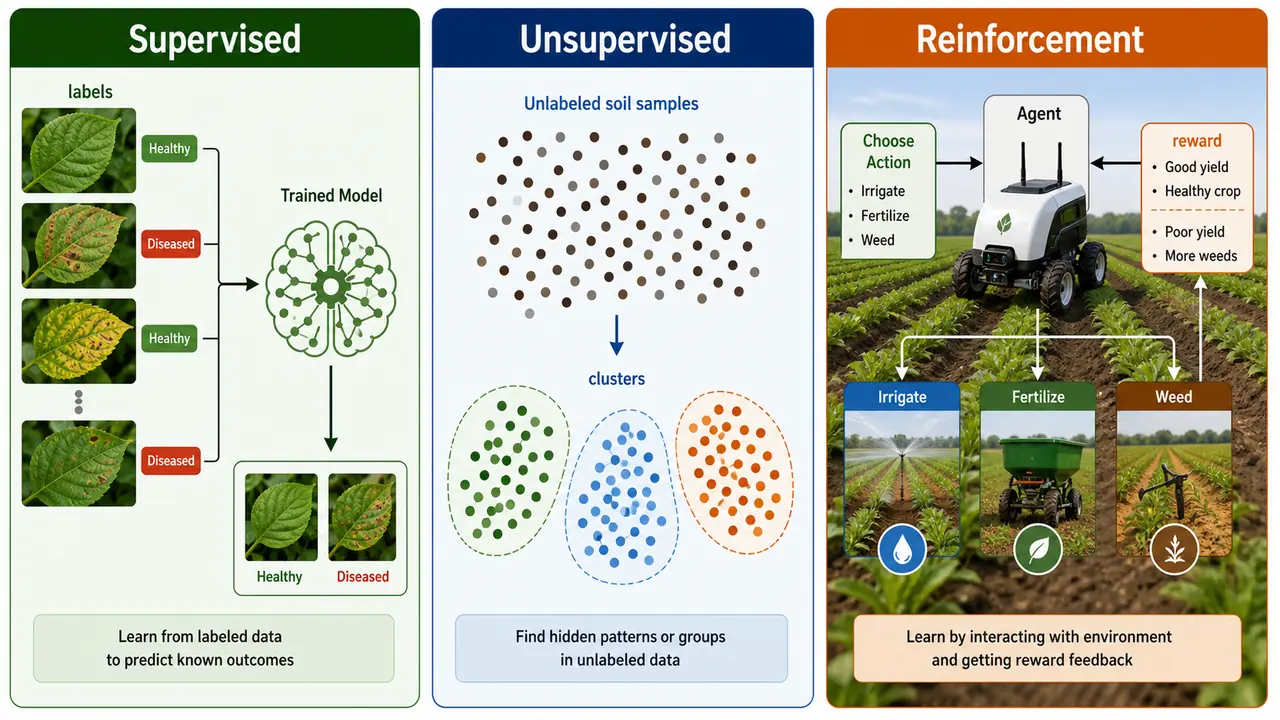
1. Supervised Learning
In Supervised Learning, the algorithm is trained on labeled data — each input has a known correct output. The model learns the mapping from inputs to outputs.
- Use case: Predicting crop yield from weather data, email spam detection, disease diagnosis
- Think of it as learning with a teacher who provides correct answers
| Algorithm | Type | Use Case |
|---|---|---|
| Linear Regression | Regression (continuous output) | Predicting price, temperature, yield |
| Logistic Regression | Classification (categories) | Yes/No predictions (spam or not) |
| Decision Tree | Both | Easy to interpret, tree-like decisions |
| Random Forest | Both | Multiple decision trees combined — more accurate |
| SVM (Support Vector Machine) | Classification | Finds best boundary between classes |
| KNN (K-Nearest Neighbors) | Classification | Classifies based on closest data points |
| Naive Bayes | Classification | Based on probability — fast, good for text |
2. Unsupervised Learning
In Unsupervised Learning, the algorithm works with unlabeled data — there are no correct answers provided. The model finds hidden patterns and groupings on its own.
- Use case: Customer segmentation, anomaly detection, market basket analysis
| Algorithm | What It Does |
|---|---|
| K-Means Clustering | Groups data into K clusters based on similarity |
| Hierarchical Clustering | Creates a tree of clusters (dendrogram) |
| PCA (Principal Component Analysis) | Reduces data dimensions while keeping important information |
3. Reinforcement Learning
Reinforcement Learning (RL) is where an agent learns by interacting with an environment, taking actions, and receiving rewards or penalties. The goal is to maximize total reward over time.
| Component | Role |
|---|---|
| Agent | The learner/decision maker |
| Environment | The world the agent interacts with |
| Action | What the agent does |
| Reward | Feedback — positive (good action) or negative (bad action) |
| Policy | Strategy the agent follows to decide actions |
- Famous example: AlphaGo by Google DeepMind — defeated world champion in the board game Go
- Used in: robotics, game playing, self-driving cars, recommendation systems
Deep Learning
Deep Learning is a subset of Machine Learning that uses neural networks with multiple layers (hence "deep") to learn complex patterns from large amounts of data.
| Network Type | Full Form | Best For | Example |
|---|---|---|---|
| CNN | Convolutional Neural Network | Image recognition, object detection | Identifying plant diseases from leaf photos |
| RNN | Recurrent Neural Network | Sequential data (text, time series) | Language translation, speech recognition |
| LSTM | Long Short-Term Memory | Long sequences with memory | Weather forecasting, stock prediction |
LSTM — Special Focus
LSTM (Long Short-Term Memory) is a special type of RNN designed to remember information for long periods. Regular RNNs struggle with long sequences (they "forget" early inputs), but LSTM solves this with a memory cell that can store, update, or discard information.
- Has three gates: Forget gate (what to discard), Input gate (what to store), Output gate (what to output)
- Used in: language models, weather prediction, crop yield forecasting from time-series data
Transfer Learning & Fine-Tuning
Transfer Learning
Transfer Learning uses a model that was pre-trained on a large dataset and applies its learned knowledge to a new, related task. Instead of training from scratch (which needs massive data and computing power), you reuse an existing model.
- Example: A model trained on millions of general images (ImageNet) can be adapted to identify crop diseases with just a few hundred crop images
- Saves time, computing resources, and requires less training data
Fine-Tuning
Fine-Tuning is the process of taking a pre-trained model and training it further on your specific dataset. You adjust the model's weights slightly to perform well on the new task.
- Transfer Learning = use the model as-is or with minor changes
- Fine-Tuning = retrain some or all layers on your specific data
Important ML Terminology
| Term | Meaning |
|---|---|
| Feature | An input variable (e.g., rainfall, soil pH, temperature) |
| Label | The output/target variable (e.g., crop yield, disease type) |
| Training Data | Data used to teach the model |
| Testing Data | Unseen data used to evaluate model performance |
| Validation Data | Data used to tune model parameters during training |
| Epoch | One complete pass through the entire training dataset |
| Batch Size | Number of samples processed before model updates its weights |
| Learning Rate | How quickly the model adjusts — too high = overshoots, too low = too slow |
| Overfitting | Model memorizes training data but fails on new data (too complex) |
| Underfitting | Model is too simple to capture patterns in data (poor performance on everything) |
What is Big Data?
Big Data refers to extremely large and complex datasets that cannot be processed by traditional database tools. It requires specialized technologies and frameworks.
The 5 V's of Big Data
| V | Meaning | Example |
|---|---|---|
| Volume | Huge amount of data | Terabytes/Petabytes of social media posts |
| Velocity | Speed of data generation | Real-time stock market data, sensor readings |
| Variety | Different types of data | Text, images, videos, sensor data mixed together |
| Veracity | Accuracy and trustworthiness | Is the data reliable or noisy? |
| Value | Usefulness of data | Can we extract meaningful insights from it? |
Types of Data
| Type | Description | Examples |
|---|---|---|
| Structured | Organized in rows/columns (tabular) | Excel sheets, SQL databases, CSV files |
| Unstructured | No predefined format | Images, videos, emails, social media posts |
| Semi-structured | Partially organized | XML, JSON, HTML files |
Hadoop Ecosystem
Apache Hadoop is an open-source framework for distributed storage and processing of large datasets across clusters of computers.
Hadoop Core Components
| Component | Full Form | Role |
|---|---|---|
| HDFS | Hadoop Distributed File System | Distributed storage — stores data across multiple machines |
| MapReduce | — | Processing framework — processes data in parallel |
| YARN | Yet Another Resource Negotiator | Resource management — allocates CPU, memory to tasks |
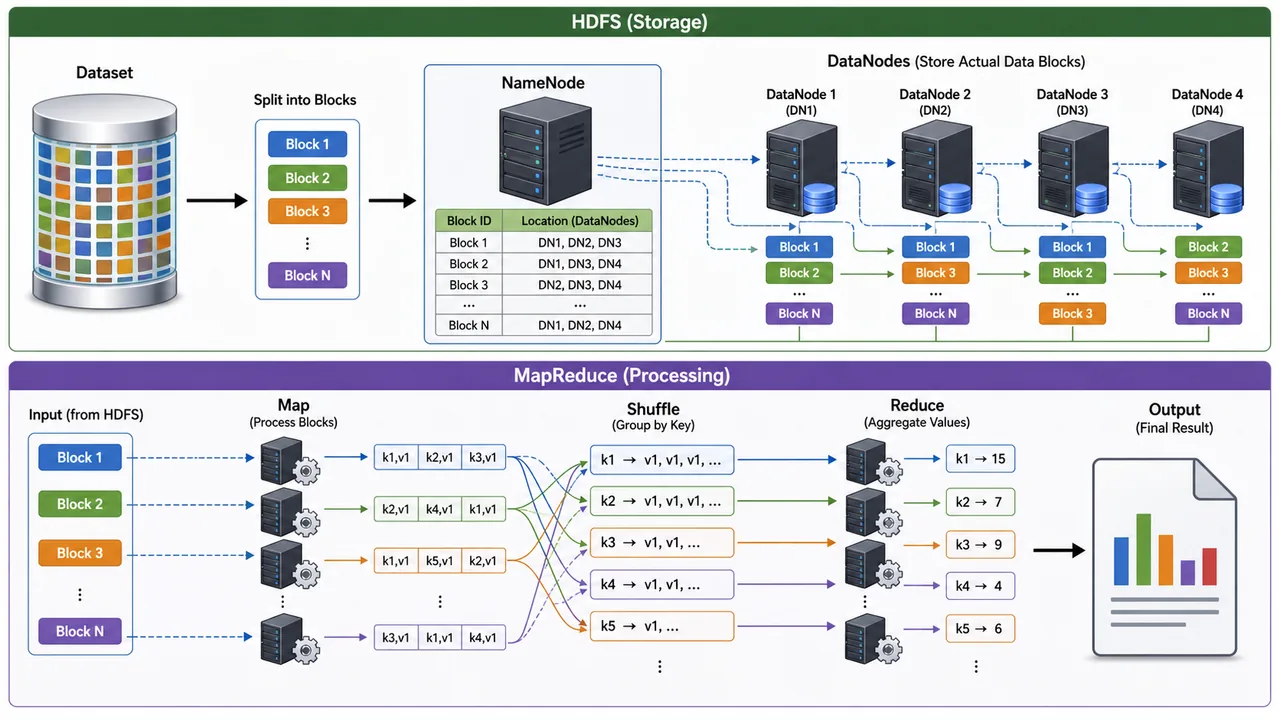
HDFS Architecture
| Component | Role |
|---|---|
| NameNode | Master node — stores metadata (file names, locations, block info). Does NOT store actual data |
| DataNode | Slave nodes — store actual data blocks. Report to NameNode periodically |
| Secondary NameNode | Creates checkpoints of NameNode metadata (NOT a backup NameNode) |
- Data is split into blocks (default 128 MB) and distributed across DataNodes
- Each block is replicated 3 times (default) for fault tolerance
MapReduce — How It Works
MapReduce processes data in two phases:
| Phase | What Happens | Example (Word Count) |
|---|---|---|
| Map | Splits input data and processes each piece independently | Each mapper counts words in its chunk |
| Shuffle & Sort | Groups intermediate results by key | All counts for same word grouped together |
| Reduce | Aggregates grouped results to produce final output | Sums up counts for each word |
Apache Spark
Apache Spark is a faster alternative to MapReduce that processes data in-memory (RAM) instead of reading/writing to disk repeatedly.
- Up to 100x faster than MapReduce for in-memory processing
- Supports batch processing, streaming, machine learning (MLlib), and graph processing
- Written in Scala, supports Java, Python, R
Data Analytics Types
| Type | Question It Answers | Example |
|---|---|---|
| Descriptive | What happened? | Last year's crop production report |
| Diagnostic | Why did it happen? | Why did yield drop in Kharif season? |
| Predictive | What will happen? | Forecasting next season's rainfall |
| Prescriptive | What should we do? | Recommending optimal fertilizer quantity |
Data Storage & Mining
| Concept | Description |
|---|---|
| Data Warehouse | Central repository of structured, historical data for analysis and reporting |
| Data Lake | Storage for raw data in any format (structured + unstructured) — process later |
| Data Mining | Discovering patterns and insights from large datasets using statistical methods |
| Visualization Tools | Tableau, Power BI — create charts, dashboards, interactive reports |
Common ML Algorithms — Exam Quick Reference
| Algorithm | Type | How It Works | Best For |
|---|---|---|---|
| KNN (K-Nearest Neighbors) | Classification | Classifies a data point based on the majority class of its K closest neighbors | Pattern recognition, recommendation systems |
| Naive Bayes | Classification | Uses Bayes' theorem — calculates probability of each class, assumes features are independent | Spam filtering, text classification, sentiment analysis |
| SVM (Support Vector Machine) | Classification | Finds the optimal hyperplane (boundary) that best separates two classes with maximum margin | Image classification, face detection |
| Decision Tree | Both | Tree-like model — splits data at each node based on a feature condition (if-then rules) | Easy to interpret, medical diagnosis |
| Random Forest | Both | Ensemble method — builds many decision trees and takes majority vote | More accurate than single tree, reduces overfitting |
Exam tip: Random Forest = many Decision Trees voting together (like asking 100 experts instead of 1).
Neural Network Activation Functions
Activation functions determine whether a neuron should be "activated" (fire) or not. They introduce non-linearity into the network.
| Function | Output Range | Use |
|---|---|---|
| Sigmoid | 0 to 1 | Binary classification (yes/no) — output layer |
| ReLU (Rectified Linear Unit) | 0 to ∞ | Most popular for hidden layers — fast, avoids vanishing gradient |
| Softmax | 0 to 1 (probabilities summing to 1) | Multi-class classification output — e.g., classifying crop disease among 10 types |
Important Training Terms
| Term | Meaning |
|---|---|
| Epoch | One complete pass through the entire training dataset |
| Batch Size | Number of training samples used in one update of model weights |
| Iteration | Number of batches needed to complete one epoch |
| Learning Rate | Controls how much weights are adjusted per update |
Example: 1,000 samples, batch size = 100 → 10 iterations per epoch.
Model Evaluation Metrics
| Metric | What It Measures |
|---|---|
| Accuracy | Overall correct predictions / total predictions |
| Precision | Of all predicted positives, how many are actually positive? (avoids false alarms) |
| Recall (Sensitivity) | Of all actual positives, how many were correctly identified? (avoids missing cases) |
| F1 Score | Harmonic mean of Precision and Recall — balances both |
Exam tip: Precision = "Don't cry wolf"; Recall = "Don't miss any wolf"; F1 = balance of both.
Big Data Tools — Additional
| Tool/Concept | What It Does |
|---|---|
| Apache Kafka | Real-time data streaming platform — handles millions of events per second (used by LinkedIn, Uber) |
| ETL (Extract, Transform, Load) | Process for moving data from source systems into a Data Warehouse: Extract raw data → Transform (clean, format) → Load into warehouse |
Data Lake vs Data Warehouse
| Feature | Data Lake | Data Warehouse |
|---|---|---|
| Data Type | Raw, unprocessed data (any format) | Processed, structured data |
| Schema | Schema-on-read (structure applied when reading) | Schema-on-write (structure defined before loading) |
| Users | Data scientists, ML engineers | Business analysts, managers |
| Cost | Lower (stores everything cheaply) | Higher (requires processing before storage) |
| Example | AWS S3, Azure Data Lake | Amazon Redshift, Google BigQuery |
Exam tip: Data Lake = dump everything raw; Data Warehouse = organized, ready-to-query data.
Summary Points
| Concept | Key Details |
|---|---|
| Machine Learning | Computers learn from data without explicit programming |
| Supervised Learning | Labeled data — regression & classification |
| Linear Regression | Predicts continuous values (price, yield) |
| Decision Tree | Tree-like decisions, easy to interpret |
| Random Forest | Multiple decision trees combined |
| SVM | Finds best boundary between classes |
| KNN | Classifies based on nearest neighbors |
| Naive Bayes | Probability-based, fast, good for text |
| Unsupervised Learning | Unlabeled data — clustering & dimensionality reduction |
| K-Means | Groups data into K clusters |
| PCA | Reduces dimensions, keeps key info |
| Reinforcement Learning | Agent + Environment + Reward + Policy |
| AlphaGo | RL example by Google DeepMind |
| CNN | Images — Convolutional Neural Network |
| RNN | Sequences — Recurrent Neural Network |
| LSTM | Long sequences with memory cells (3 gates) |
| Transfer Learning | Reuse pre-trained model for new task |
| Fine-Tuning | Retrain pre-trained model on specific data |
| Overfitting | Model too complex, fails on new data |
| Underfitting | Model too simple, poor on all data |
| Big Data 5 V's | Volume, Velocity, Variety, Veracity, Value |
| Structured Data | Rows/columns (Excel, SQL) |
| Unstructured Data | No format (images, videos, emails) |
| HDFS | Hadoop distributed storage system |
| NameNode | Master — stores metadata, not data |
| DataNode | Slave — stores actual data blocks |
| MapReduce | Map (split & process) → Reduce (aggregate) |
| Apache Spark | In-memory processing, 100x faster than MapReduce |
| YARN | Resource manager in Hadoop |
| Data Warehouse | Structured historical data for analysis |
| Data Lake | Raw data in any format |
| Data Mining | Discover patterns from large datasets |
| Tableau / Power BI | Data visualization tools |
| Descriptive Analytics | What happened? |
| Diagnostic Analytics | Why did it happen? |
| Predictive Analytics | What will happen? |
| Prescriptive Analytics | What should we do? |
| Epoch | One complete pass through training dataset |
| Batch Size | Samples processed before model weight update |
| Learning Rate | How much weights adjust per update |
| Precision | Of predicted positives, how many are correct? |
| Recall | Of actual positives, how many were found? |
| F1 Score | Harmonic mean of Precision and Recall |
| Sigmoid | Activation 0-1, binary classification output |
| ReLU | Activation 0-infinity, most popular for hidden layers |
| Softmax | Activation probabilities summing to 1, multi-class output |
| Apache Kafka | Real-time data streaming — millions of events/sec |
| ETL | Extract, Transform, Load — data into warehouse |
| Data Lake | Raw data, any format, schema-on-read (AWS S3) |
| Data Warehouse | Processed structured data, schema-on-write (Redshift, BigQuery) |
Lesson Doubts
Ask questions, get expert answers